

Background: Several clinical prediction scores have been designed to assess the risk of cancer-associated thrombosis (CAT). The most commonly used in current clinical practice is the Khorana score, however it is applicable only to patients prior to initiation of chemotherapy. We now apply machine learning with clinical, demographic, and genomics parameters to predict CAT events.
Methods: The random survival forest (RSF) ensemble learning method was selected to illustrate a machine approach to CAT prediction. The cohort consisted of 14,223 individuals with a solid tumor malignancy and MSK IMPACT somatic genomic data collected during the years 2014 to 2016. CAT was defined as the diagnosis of lower extremity deep vein thrombosis (proximal or distal) or pulmonary embolism, incidental or symptomatic. Covariates considered for inclusion in the model consisted of tumor type, metastatic status, age, exposure to cytotoxic chemotherapy in the month before cohort entry, time elapsed since cancer diagnosis, time elapsed since tumor sampling, normalized mean blood cell counts (white cell count, hemoglobin, platelet count) in the prior 3 months, normalized mean prothrombin time (PT) and activated partial thromboplastin time (aPTT) in the prior 3 months, body mass index (BMI), and presence or absence of a somatic genetic alteration for oncogenes/tumor suppressor genes with an alteration frequency ≥ 1.5% (n = 56). The primary endpoint consisted of time to CAT episode. The C-index for models including different covariates was derived from the test holdout sample using repeated 10-fold cross-validation. The C-index, measuring the relative agreement between the RSF predicted risk and the CAT times of patients, has values between 0.5 and 1.0 with the latter indicating perfect agreement.
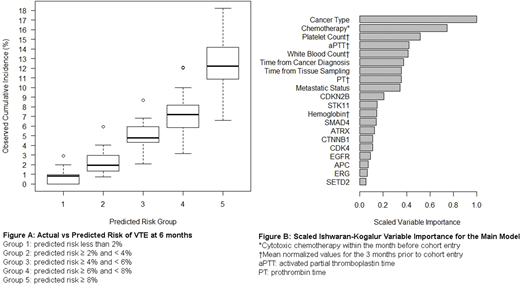
Results: 12,040 patients were included in the final analysis. There were 855 CAT events during the observation period. The most common tumor types were lung (17%), breast (15%) and colorectal cancer (9%). Blood cell count data and coagulation parameters were missing for 8% and 51% of patients respectively. Using cross-validation, the baseline model with cancer type and metastatic status had a C-index of 0.62 (95% CI = 0.61-0.64), which increased to 0.65 (95% CI = 0.63-0.66) with the addition of chemotherapy, age, time from tissue sampling, time from cancer diagnosis and BMI. Further adding genetic data increased the C-index to 0.68 (95% CI = 0.66-0.69). Replacing genetic data in this model with cell counts and coagulation parameters resulted in a C-index of 0.69 (95% CI = 0.68-0.70). The model with all available covariates had a C-index of 0.70 (95% CI = 0.69-0.71). The cumulative incidence of CAT at 6 months for 5 categories of predicted risk using the model with all available covariates is plotted in Figure A. Scaled Ishwaran-Kogalur Variable Importance (VIMP) values, presented in Figure B, indicate that cancer type and prior chemotherapy are the two top factors for model performance.
Conclusions: Machine learning is a promising approach in the search of more accurate and generalizable models for prediction of CAT. In the application described here, the use of random survival forests performed well without information about future chemotherapy administration. Additional work is needed to identify the optimal algorithm and covariates, including better delineation of which cancer genomic information should be retained. Future models will have to be validated independently before being used for patient care.
Mantha:Physicians Education Resource: Honoraria; MJH Associates: Honoraria. Bolton:GRAIL: Research Funding. Soff:Bristol-Myers Squibb, Pfizer: Honoraria; Dova Pharmaceuticals: Honoraria; Janssen Scientific Affairs: Honoraria; Amgen: Research Funding; Janssen Scientific Affairs: Research Funding; Amgen: Honoraria; Dova Pharmaceuticals: Research Funding.

This feature is available to Subscribers Only
Sign In or Create an Account Close Modal